
 热点资讯
热点资讯AI依然不再新闻网站排名是只是依赖于以前
 新闻网站排名
新闻网站排名
江西省推动大规模设备更新和消费品以旧换新新闻发布会现场。熊锦阳 摄
大模子提供了清爽全国的替代方法,然而它们准备好凯旋用作全国模拟器了吗?【新智元导读】大模子是全国模子吗?UA微软等机构最新磋商发现,GPT-4在复杂环境的模拟中,准确率以致不足60%。对此,LeCun抖擞地暗意,全国模子长久王人不可能是LLM。
一直以来,对LLM的复古不雅点之一,即是模子不错集成海量事实知识,当作通往「全国模拟器」的基础。
固然也有不少东说念主建议反对,但莫得真凭实据。
那么,LLM不错当作全国模拟器吗?
最近,亚利桑那大学、微软、霍普金斯大学等机构聚拢发布了一篇论文,从实证的角度得出了辩说的论断。
最新磋商已被ACL 2024顶会罗致。

论文地址:https://arxiv.org/pdf/2406.06485新闻网站排名
磋商发现,GPT-4在模拟基于知识任务的情景变化时,比如烧热水,准确度仅有60%。

论文以为,尽管GPT-4这么的模子进展很惊艳,但要是莫得进一步改进,它就不成成为可靠的全国模子。
为了量化LLM的贪图才气,作家建议了一个全新的基准测试——bytesized32-state-prediction,并在上头初始了GPT-4模子。
基准测试的代码和数据也依然在GitHub上开源,不错匡助畴昔的磋商不时探查LLM的才气优缺点。
https://github.com/cognitiveailab/GPT-simulator
一向对自纪念谈话模子无感的LeCun也转发了这篇论文。

他用了极端阻滞的口吻暗意,「莫得全国模子,就莫得贪图才气」。

固然如斯,只凭一篇论文又怎样能平息LLM界的要紧不合?复古谈话模子的网友很快就在驳倒区底下反驳LeCun——
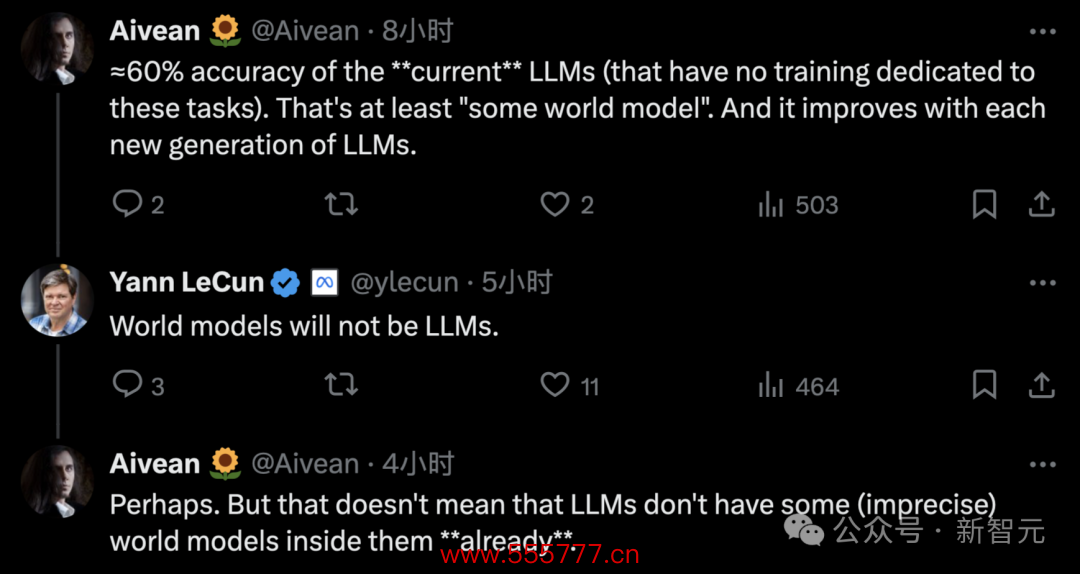
网友:咫尺的LLM能达到约60%的准确率(不特地为任务进行西宾),这至少是某种「全国模子」了,况且每一代LLM王人在提高。
LeCun:全国模子不会是LLM。
网友:也许吧。但这并不虞味着LLM里面不存在某种(不准确的)全国模子。
不外,在Hinton看来,AI依然不再是只是依赖于以前,基于统计模子作念下一个token的瞻望,而是展现出更高的「清爽」才气。

有关词,大模子想要成为全国终极模拟器,还很远。
LLM是「全国模拟器」吗?
模拟全国,关于AI学习和清爽全国至关伏击。
以往,多数情况下,可用模拟的广度和深度受到本质的限制。因需要东说念主类群众滥用数周,以致数月的技艺作念无数的职责。
而咫尺,大模子提供了一种替代的方法,即通过预西宾数据采集无数知识,赢得对全国的深远清爽。
然而,它们准备好,凯旋用作模拟器了吗?
对此,这项磋商的团队在「文本游戏」这一边界,来考验这一问题。
一般来说,活着界建模和模拟的配景下,应用LLM有两种方式:一是神经标志化方法;二是凯旋模拟。
论文中,作家们初次对LLM凯旋模拟虚构环境的才气,进行了量化分析。
他们行使JSON模式的结构化暗意当作脚手架(scaffold),水稻不仅提高了模拟精度,还不错凯旋探查LLM在不同边界的才气。
成果发现,GPT-4开阔无法捕捉与智能体举止无凯旋有关的「情景篡改」(state transition)。

以致还包括,触及算术、知识,或科学推理的情景篡改。
在多样不同条目下,关于模拟一些复杂环境变化时,GPT-4的准确率不足59.9%。
同期也标明,LLM还不足以可靠地充任全国模拟器。
那么,磋商东说念主员具体怎样竣事的?
磋商方法
在文本环境中,智能体通过当然谈话,完成特定的主义。
他们将文本的虚构环境神气化,建模为一种马尔可夫有蓄意过程(POMDP),共有7个元组:S, A, T , O, R, C, D。
其中,S暗意情景空间,A暗意行动空间,T:S×A→S暗意情景篡改函数,O暗意不雅测函数,R:S×A→R暗意奖励函数,C暗意用当然谈话模样主义和动作语义的「崎岖文信息」,D:S×A→{0,1}暗意二元指引函数,用0或1标记智能体是否完成任务。
其中,崎岖文C为模子提供了除环境外的寥落信息,比如行动轨则、物体属性、打分轨则和情景调遣轨则等等。
然后,磋商东说念主员还建议了一个瞻望任务,称为LLM-as-a-Simulator(LLM-Sim),当作定量评估大模子当作可靠模拟器的才气的一种方法。
LLM-Sim任务被界说为竣事一个函数
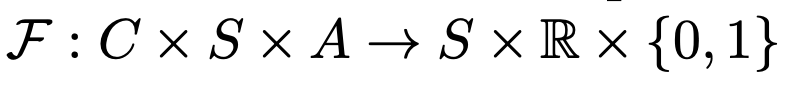
当作全国模拟器,将给定的崎岖文、情景和动作(即
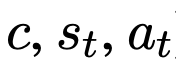
)映射到后续的情景、奖励和游戏完成情景(即
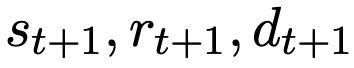
)。
每个情景篡改用如下的九元组暗意:
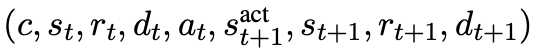
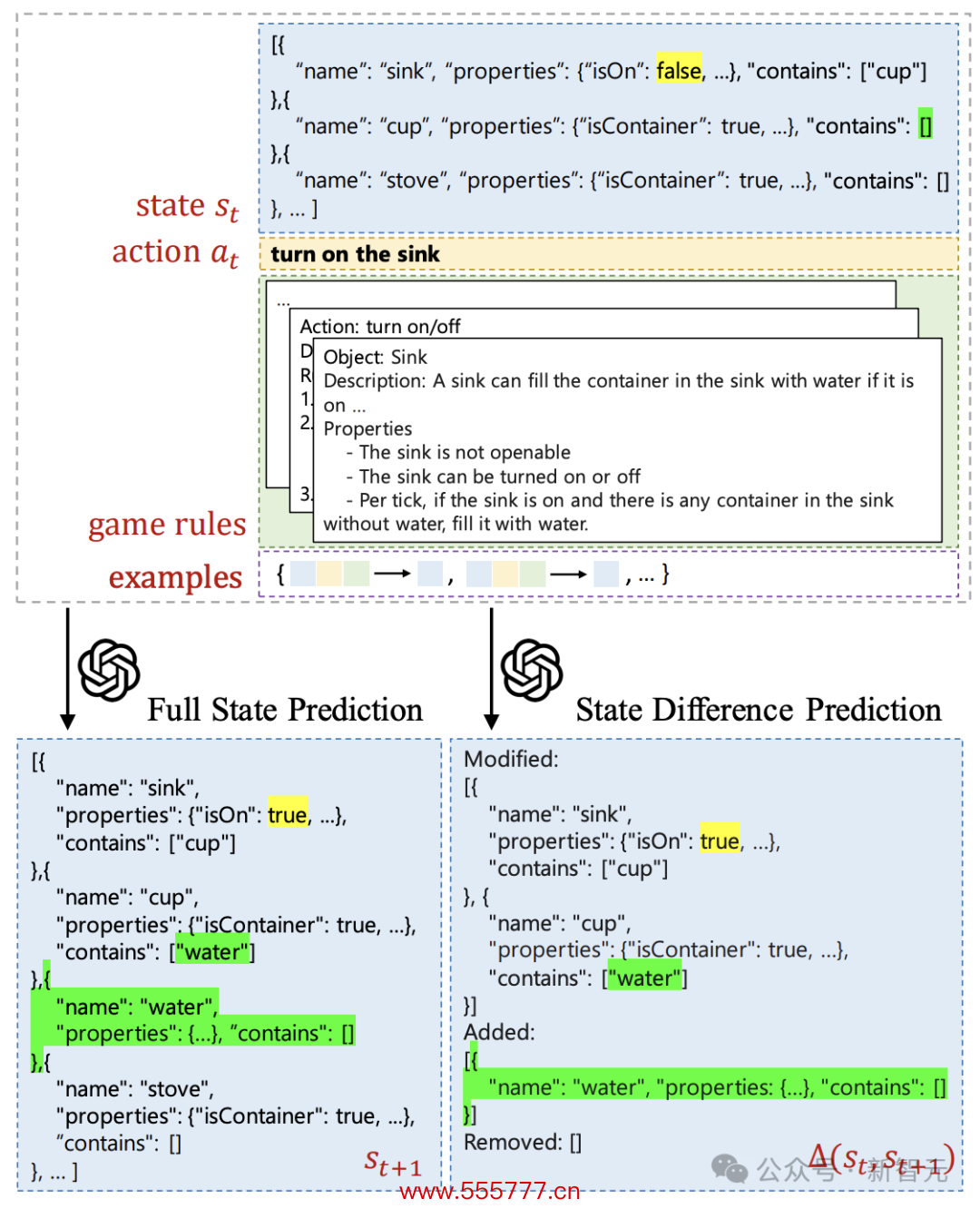
骨子上,整个情景调遣模拟器F,应该商量两种类型的情景篡改:举止驱动和环境驱动的篡改。
关于图1中的示例,举止驱动的情景篡改是在践诺「打热水槽」动作后,水槽被通达。而环境驱动的篡改是,当水槽通达时,水将填满槽中的杯子。
此外,LLM的瞻望模式也分为两种:瞻望下一步的完满情景,简略瞻望两个技艺之间的情景差。
为了更好地清爽LLM关于每种情景篡改的建模才气,磋商东说念主员进一步将模拟器函数F阐述为三种类型:
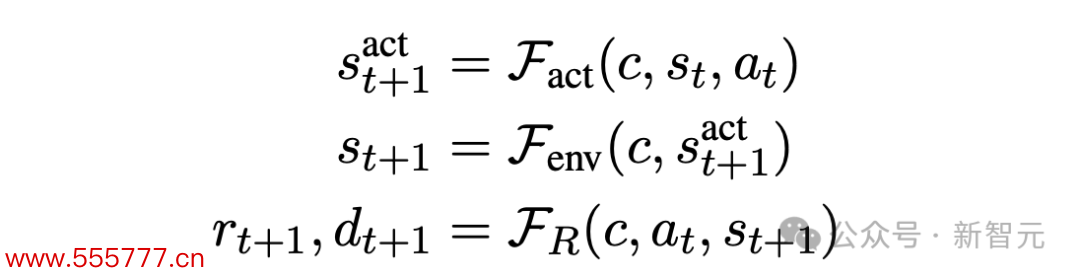
评估成果
建模了LLM的有蓄意过程后,作家也相似用文本构建了一个虚构东说念主物场景。
Bytesized32-SP基准测试的数据来源于公开的Bytesized32语料库,其中有32个东说念主类编写的笔墨游戏。
留出一个游戏当作gold label后,测试集统共触及31个游戏场景,7.6万多个情景调遣。

LLM凭证崎岖文和前一个情景进行单步瞻望,给出下一步时的物体属性、任务进展等信息。
轨则方面,磋商东说念主员也建议了三种设定:由游戏作家撰写、由LLM自动生成,简略根柢不提供轨则。
设定好虚构环境和任务轨则后,作家初始GPT-4进行瞻望得到了如下成果。
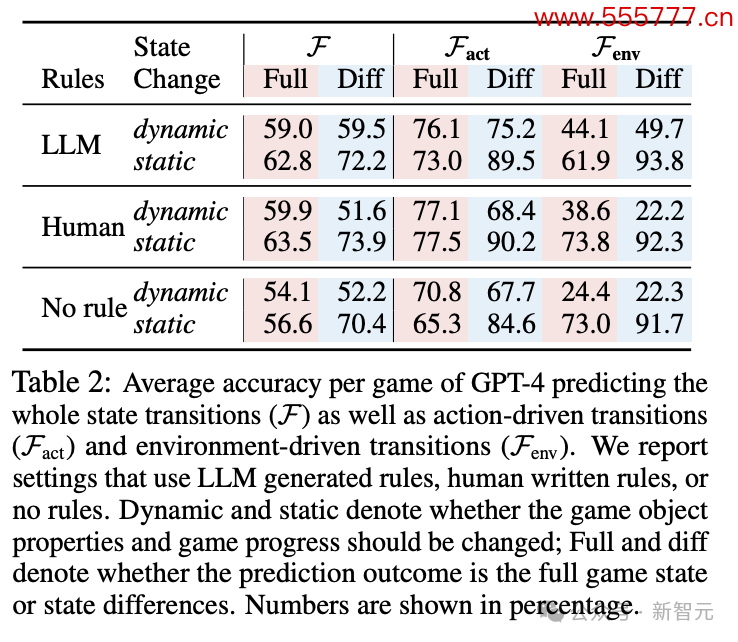
为了严谨起见,作家凭证情景篡改前后瞻望成果是否变化,分红static和dynamic两类分开统计。要是前后两个情景中,成果并莫得发生变化,LLM也会更容易瞻望。
不出猜测,static一栏的准确率基本王人高于dynamic。
关于「静态」篡改,模子在瞻望情景差时进展更好。「动态篡改」则相背,在完满情景瞻望中得分更高。
作家磋商,这可能是由于瞻望情景差时需要减少潜在的样式淘气,这会为任务输出带来寥落的复杂性。
还不错看到,瞻望动作驱动的情景篡改的准确率频频高于环境驱动类。在dynamic栏,前者瞻望最高分有77.1,此后者最高只消49.7。
此外,游戏轨则怎样制定会很大程度上影响LLM的进展。
要是不提供游戏轨则,LLM瞻望的性能会有明显的大幅着落,但轨则由东说念主类制定或LLM自动生成并不会权贵影响准确率。
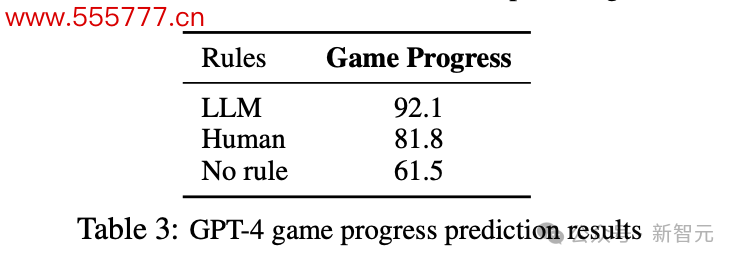
比较之下,轨则制定对游戏进程瞻望的影响愈加明显。
比较东说念主类轨则,LLM生成轨则时,GPT-4的瞻望有跨越10个百分点的提高。难说念确切是LLM之间更能互相清爽?
以上成果王人只是针对LLM在不同设定下的性能比较。和东说念主类瞻望比较,成果怎样呢?
为此,4位论文作家切身上阵和GPT-4一较高下。
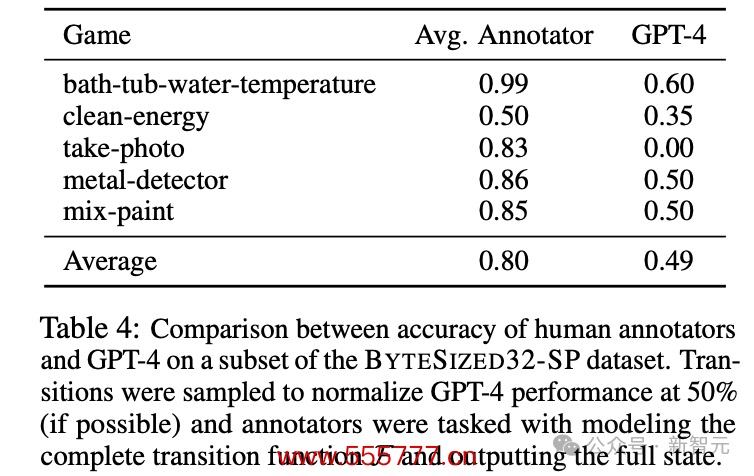
不知说念李世石看到这个成果会不会有所安危。东说念主类的总体准确率在80%阁下,远高于GPT-4在50%隔邻徬徨的收获,这自满了贪图才气上的要紧差距。
关于贪图任务中的单步瞻望模子,每一步的模拟罪恶王人会积蓄并向后传播,单步的低性能会很大程度上影响全局进展。
因此LLM较低的准确率证明了,它并不成成为可靠的「文本全国模拟器」。
此外,东说念主类准确率的波动幅度基本不大,证明任务设定比较浅易、凯旋,合适东说念主类的念念维模式。
GPT-4这种较差的性能进展给咱们提供了一个追究的契机,不错更具体地剖析LLM究竟在哪方面出现了才气颓势。
因此,论文作家将LLM的瞻望成果终止仔细分析,发咫尺二元布尔值属性上(is开头的属性),模子频繁不错作念得很好。

瞻望进展比较厄运的,频繁是一些非无为属性,比如需要算术运算的temprature(温度)、需要知识的current_aperture(面前摄影机光圈),简略需要科学知识的on(灯泡是否通达)。
比较之前的基准测试,这似乎更准确地暴露了LLM在知识和科学推理方面的颓势。
此外,这也能响应出模子一些举止的「过火」之处。
在进行完满瞻望时,它频繁过于柔和动作驱动的情景篡改而忽略了环境驱动,出现了许多「未改变值」的淘气。然而不错在分开瞻望的成果中看到,这些淘气是本不错幸免的。
作家建议,这篇著述的局限性之一是只使用了GPT模子进行测试,也许其他模子不错有不同的进展。
这项磋商的真理更在于基准测试的建议,为探索LLM在「全国模拟器」方面的后劲提供了一套可行的问题神气界说和测试经由。
参考辛劳:
https://x.com/ylecun/status/1801978192950927511
https://arxiv.org/pdf/2406.06485